

分享会
为什么要有分享会
一个人的时间是有限的
什么是npm?
- npm 全拼为 Node Package Manager,是 JavaScript 软件包管理器
npm install X:
会把X包安装到node_modules目录中
不会修改package.json
之后运行npm install命令时,不会自动安装X
npm install X –save:
会把X包安装到node_modules目录中
会在package.json的dependencies属性下添加X
之后运行npm install命令时,会自动安装X到node_modules目录中
之后运行npm install –production或者注明NODE_ENV变量值为production时,会自动安装msbuild到node_modules目录中
npm install X –save-dev:
会把X包安装到node_modules目录中
会在package.json的devDependencies属性下添加X
之后运行npm install命令时,会自动安装X到node_modules目录中
之后运行npm install –production或者注明NODE_ENV变量值为production时,不会自动安装X到node_modules目录中
npm install 安装某个指定的版本
1 |
|
如何拥有自己的第一个 npm 包?
去npm官网注册一个自己的账号
新建一个项目=>
npm init生成package.json文件=>新建一个index.js
1
2
3module.export.getNpmPackages=()=>{
console.log('新建一个npm包')
}新建一个README.md文件
把当前npm路径指向到npm
1
npm config set registry http://registry.npmjs.org/
上传
npm login然后npm publish什么是const
- 常量是块级作用域,很像使用
let语句定义的变量。常量的值不能通过重新赋值来改变,并且不能重新声明。 - const声明的变量不得改变值,这意味着,const一旦声明变量,就必须立即初始化,不能留到以后赋值。
- 关于“暂存死区”的所有讨论都适用于let和const。
const声明创建一个值的只读引用。但这并不意味着它所持有的值是不可变的,只是变量标识符不能重新分配。例如,在引用内容是对象的情况下,这意味着可以改变对象的内容(例如,其参数)。MDN描述
const 无法改变指针的指向
const实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址所保存的数据不得改动。对于简单类型的数据(数值、字符串、布尔值),值就保存在变量指向的那个内存地址,因此等同于常量。- 但对于复合类型的数据(主要是对象和数组),变量指向的内存地址,保存的只是一个指向实际数据的指针,
const只能保证这个指针是固定的(即总是指向另一个固定的地址),至于它指向的数据结构是不是可变的,就完全不能控制了。
为啥用const不用let
我们在javascript中有3种声明变量的方式:var,let,const;
其中var和let声明的是变量,而const声明的叫做常量,那我们想一个问题,我们声明一个变量后,我们不去管它,不去修改它,那它不就也是所谓意义上的常量了吗,为什么还要存在const呢?
- const它有一个独特的存放值的空间,而var和let就没有,我们用const声明的常量都会放到它独有的空间里面,当我们跑代码的时候,如果我们用的是var或let声明的变量,我们电脑找一个变量的时候,就会一个一个的去找,因为javascript是单线程的,代码会从上往下依次执行,所以找起来就会很慢,但当我们用const的时候,电脑就会默认从它独有的空间里去找,就快了很多,没有去跑那些不必要跑的路。
- const 相比 let ,减少了未来变化的可能性,对于项目而言,变化少的情况下,安全性会稍微高一点点;
- 它告诉其他阅读您的代码的人您不打算更改该值。
- 如果您执行某些操作会改变变量的值而不必这样做,则会给您一个很好的主动错误。(智能IDE可以主动对其进行标记。)
通过idea把没有改变的变量变成const
eslint 有个 规则 prefer const,如果配置了这条 ESLint 规则(或者引用的第三方 ESLint 库配置了),且编辑器有自动格式化或者项目有提交前格式化的功能,那么代码里所有的未重新赋值的 let 会自动被改成 const(实际上,你看到的多是 const 也往往是这么产生的,毕竟 const 打起来麻烦一点)
js对象的直接赋值、浅拷贝与深拷贝(shallow copy 、deep copy)
1 | const arr1=[1,23] |
- 两个Object类型对象,即使拥有相同属性、相同值,当使用 == 或 === 进行比较时,也不认为他们相等。这就是因为他们是通过引用(内存里的位置)比较的,不像基本类型是通过值比较的。js数据类型,由于内存地址我们很难监测到,但是我们可以通过严格相等运算符”===”来检测二者是否指向同一个地址。
1 | personCopy.name='小东' |
- 给
personCopy的name属性赋值小东,发现,person也发生了改变。即:直接赋值,修改赋值后的对象b的非对象属性,也会影响原对象a的非对象属性;修改赋值后的对象b的对象属性,也会影响原对象a的对象属性。
原因如下图:
浅拷贝
浅拷贝只会赋值制对象的非对象属性,不会指向同一个地址 - ES6中有个浅拷贝的方法Object.assign(target, …sources)
1 | const person={ |
修改赋值后的对象b的非对象属性,不会影响原对象a的非对象属性;修改赋值后的对象b的对象属性,却会影响原对象a的对象属性
1 | const person={ |
es6中还有一个扩展运算符”…”也可以实现浅拷贝1
2
3
4
5
6
7
8
9
10const person={
name:'小明',
ageAndSex:{
age:18,
sex:'男'
}
}
let personCopy = {...person}
personCopy=== person // false
personCopy.ageAndSex.age=20或者用for in 循环
1 | var person={name:"小明",ageAndSex:{age:16,sex:"男"}} |
深拷贝
深拷贝会另外拷贝一份一个一模一样的对象,但是不同的是会从堆内存中开辟一个新的区域存放新对象,新对象跟原对象不再共享内存,修改赋值后的对象b不会改到原对象a。即深拷贝,修改赋值后的对象b的非对象属性,不会影响原对象a的非对象属性;修改赋值后的对象b的对象属性,也不会影响原对象a的对象属性。而且,二者不指向同一个对象。
可以用继续用for in + 递归
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17var person={name:"小明",ageAndSex:{age:16,sex:"男"}}
// 深拷贝 , 递归调用
var deepCopy = function(obj) {
if (typeof obj !== 'object') return;
// 根据obj的类型判断是新建一个数组还是对象
var newObj = obj instanceof Array ? [] : {};
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = typeof obj[key] === 'object' ? deepCopy(obj[key]) : obj[key];
}
}
return newObj;
}
let personCopy= deepCopy(person)
personCopy=== person // false
personCopy.ageAndSex.age=20一种非常简单的方法就是序列化成为一个JSON字符串,将对象的内容转换成字符串的形式,再用JSON.parse()反序列化将JSON字符串变成一个新的对象
1 | var person={name:"小明",ageAndSex:{age:16,sex:"男"}} |
JSON.stringfy 和 JSON.parse
但是由于用到了JSON.stringify(),这也会导致一系列的问题,因为要严格遵守JSON序列化规则:原对象中如果含有Date对象,JSON.stringify()会将其变为字符串,之后并不会将其还原为日期对象。或是含有RegExp对象,JSON.stringify()会将其变为空对象,属性中含有NaN、Infinity和-Infinity,则序列化的结果会变成null,如果属性中有函数,undefined,symbol则经过JSON.stringify()序列化后的JSON字符串中这个键值对会消失,因为不支持。
但是该方法有以下几个问题:
(1)会忽略 undefined
(2)会忽略 symbol
(3)不能序列化函数
(4)不能解决循环引用的对象
(5)不能正确处理new Date()
(6)不能处理正则
其中(1)(2)(3) undefined、symbol 和函数这三种情况,会直接忽略。
1 |
|
forEach不改变原数组但是改变对象属性的问题
- forEach(item, index, arr),三个参数,如果直接用item=xxx是无法改变原数组的,但是如果用arr[index]就可以改变原数组。
1 |
|
- 数组里面的子元素是对象,那么是可以改变对应属性的
1 |
|
foeEach其实就是语法糖
实现原声forEach
1 | Array.prototype._forEach = function(fn) { |
所以修改数组中的对象的值就可以改变原数组。
js数据类型
基本类型
js中有5种数据类型:Undefined、Null、Boolean、Number和String。
- 任何方法都无法改变一个基本类型的值,比如一个字符串:
1 | var name = 'jay'; |
会发现原始的name并未发生改变,而是调用了toUpperCase()方法后返回的是一个新的字符串。
基本类型的变量是存放在栈区的(栈区指内存里的栈内存)
1 | var name = 'jozo'; |
那么它的存储结构如下图:如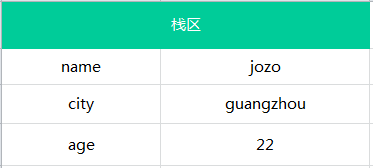
栈区包括了 变量的标识符和变量的值。左边是变量右边是值
引用类型
还有一种复杂的数据类型Object,Object本质是一组无序的名值对组成的。
javascript中除了上面的基本类型(number,string,boolean,null,undefined)之外就是引用类型了,也可以说是就是对象了。对象是属性和方法的集合。 也就是说引用类型可以拥有属性和方法,属性又可以包含基本类型和引用类型。
引用类型的值是同时保存在栈内存和堆内存中的对象
1 | var person1 = {name:'小明'}; |
这三个对象的在内存中保存的情况如下图: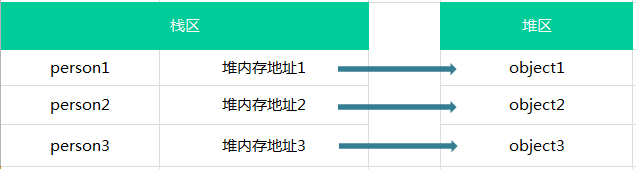
1 | var a = {}; // a保存了一个空对象的实例 |
他们的结构如下图:
引用类型的赋值其实是对象保存在栈区地址指针的赋值,因此两个变量指向同一个对象,任何的操作都会相互影响。
也就是平时
this指向的问题
什么是Promise?
- promise的意思是承诺,有的人翻译为许愿,但它们代表的都是未实现的东西,等待我们接下来去实现。
- Promise最早出现在commnjs,随后形成了Promise/A规范。
- promise的状态只能从 未完成->完成, 未完成->失败 且状态不可逆转。
- promise的异步结果,只能在完成状态时才能返回,而且我们在开发中是根据结果来选择来选择状态的,然后根据状态来选择是否执行then()。
- 实例化的Promise内部会立即执行(内部相当于同步),then方法中的异步回调函数会在脚本中所有同步任务完成时才会执行。因此,promise的异步回调结果最后输出。示例代码如下:
1 | new Promise((resolve, reject) => { |
注意:promise实例内部的resolve也执行的是异步回调,所以不管resolve放的位置靠前还是靠后,都要等内部的同步函数执行完毕,才会执行resolve异步回调。
Promise 玩法
- then方法中 永远 return 或 throw
- 如果 promise 链中可能出现错误,一定添加 catch
- 永远传递函数给 then 方法
- 不要把 promise 写成嵌套
常见的Promise错误用法
怎么用对链式调用?
- 不好的写法:
1
2
3
4
5
6userApi.getUsrInfo({id:1}).then(userInfo=>{
userApi.post({name:uerInfo.name}).then( data=>
doSomethine(data)
// ...
)
}).catch(err=>console.log(err))
我们确实可以将 promise 当做回调函数来使用,只是浪费了 Promise 的特点了(链式调用),代码也不够清晰。
我们可以写成这样
1 | userApi.getUsrInfo({id:1}) |
什么是promise穿透问题?
什么是 promise 穿透我们可以看这样的代码,下面的代码会输出什么?
1 | Promise.resolve('foo').then(Promise.resolve('bar')).then(function (result) { |
第一反应应该都觉得是输出的是 bar,那么就真的错了。实际上它输出的是 foo!
产生这样的输出是因为你给 then 方法传递了一个非函数(比如 promise 对象)的值,代码会这样理解:then(null),因此导致前一个 promise 的结果产生了坠落的效果。 比如下面的代码
1 | Promise.resolve('foo').then(null).then(function (result) { |
如何把Jquery ajax 改成链式调用?
1 |
|
如何实现简易版Axios?
1 | const axios = function (config) { |
Promise.all
1 | function promiseAll(iterable){ |
Promise.race
- Promise.race() 跟 Promise.all() 一样接收的都是数组
race顾名思义就是比赛,返回第一个执行完毕的promise的结果
1 | function httpAction(){ |
特性
Promise.race只返回第一个执行完毕的promise的结果,无论结果是fullfilled还是rejected。1
2
3
4
5Promise.race([httpAction(),testApi()]).then(res => {
console.log(res);
}).catch(err=>{
console.log(err);
});
我们可以拿 Promise.race 测试接口的反应速度
Promise.all和Promise.race传入的参数是数组,数组里的项且是Promise1
Promise.race([Promise,Promise])
1 | var p1 = Promise.resolve(1), |
- 在上面的方法中,promise数组中所有的promise实例都变为resolve的时候,该方法才会返回,并将所有结果传递results数组中。promise数组中任何一个promise为reject的话,则整个Promise.all调用会立即终止,并返回一个reject的新的promise对象。reject使用示例如下:
1
2
3
4
5
6
7
8
9
10var p1 = Promise.resolve(1),
p2 = Promise.reject(2),
p3 = Promise.resolve(3);
Promise.all([p1, p2, p3]).then(function (results) {
//then方法不会被执行
console.log(results);
}).catch(function (e){
//catch方法将会被执行,输出结果为:2
console.log(2);
})
promise存在的问题
promise一旦执行,无法中途取消
promise的错误无法在外部被捕捉到,只能在内部进行预判处理
promise的内如何执行,监测起来很难
自定义的Promise测试
对于自定义的Promise类库,是否符合 Promise/A+ 的标准呢?
社区有一个开源的测试脚本
只需两步,就能检验我们的实现是否符合标准了
1 | //全局安装 |
鸡汤~但是确实很有用
语雀摘记
对前端来说,我们的客户既有商家、用户等最终客户,也有产品、运营、技术等业务合作上的直接客户。对直接客户,我们习惯称之为业务方。前端需要为最终客户创造客户价值,同时需要处理好业务方的客户感受。 -玉伯
lweein:一个人在工作中的工作完成度和完成质量,是和薪资有直接关系,拿多少钱做出多少事,一件老板100%需求的工作。完成了80%,这叫合格的员工。完成100%。这叫优秀的员工。能够做到120%以上。才是超出了预期。很多时候的现实是,老板给100%的目标,期望员工做到120%的惊喜,但是只能给60%的薪资,而结果是员工做到80%的完成度,当然80%也已经不错了,也会出现60%都不够的情况。
一个人真的能够成长,能够卓越,依靠的并不是两只手的工作能力,而是意志力和格局。也就是说,如何做到拿着60%的薪资,做着80%的工作,完成100%的目标,追求120%的卓越。几乎每个人说,拿多少钱做多少事,那么这个就是格局。虽然我也很蛋疼每天讲理想不给足钱的类型。–字节跳动·竹隐
有一句很重要的话,你所做的每一件事都是有价值的,区别在于早一点还是晚一点。当然,具体执行过程中,还是考验老板对格局,意志力,金钱的平衡,马儿要跑。还是要吃点夜草的。
酷 壳 – COOLSHELL -陈皓
“在你40岁,在父亲病重,孩子上学问题、房贷并未还清、你是全家唯一收入来源之类的中年危机的情况下,辞去你现在的工作,不加入任何一家公司,不用自己的任何一分钱积蓄,不要任何人的投资和帮助。只通过自己的技术能力,为别人解决相应的技术难题(不做任何无技术含量的外包项目),来生存养家,并除了能照顾好自己的家人没有降低自己的生活水平之外,还能再养活3个每人年薪36万元的工程师”作者博客
1)软件工程师分工分得越细这个团队就越没效率,团队间的服务化是关键的关键。不管是从语言上还是从软件模块上的人员分工,越细越糟糕。服务化不是我要帮你做事,而是我让你做起事来更容易。
2)你总需要在一个环节上认真,这个环节越往前就越有效率,越往后你就越没效率。要么你设计和编码认真点,不然,你就得在测试上认真点。要是你设计、编码、测试都不认真,那你就得在运维上认真,就得在处理故障上认真。你总需要在一个地方认真。另外一篇文章你可以看一下——《多些时间少写些代码》
3)“小而精的团队”+“条件和资源受限”是效率的根本。只有团队小,内耗才会小,只有条件或资源受限,才会逼着你去用最经济的手段做最有价值的事,才会逼着你喜欢简单和简化。
4)技术债是不能欠的,要残酷无情地还债。很多事情,一开始不会有,那么就永远不会有。一旦一个事情烂了,后面只能跟着一起烂,烂得越多,就越没有人敢去还债。
5)软件架构上要松耦合,团队组织上要紧耦合。
6)工程师文化是关键,重视过程就是重视结果。只重视结果的KPI等同于“竭泽而渔”和“饮鸩止渴”。
Why review code?(为什么需要代码评审)
A friend asked me recently why it s valuable to do code review. Most Silicon Valley tech companies, at least, do code review on every change to get at least two sets of eyes on it. At one of my earlier jobs we did opt-in code review (rarely) for a while, then a new employee coming from Google joined us and encouraged us to review all our code which we did. It was a great decision. If you do it right, code review shouldn t feel onerous. You and your reviewer aren t adversaries; you re working together to build the best software you can together. (It s important to not take feedback personall
最近一个朋友问我,为什么做代码评审很有价值。至少,大多数硅谷的科技公司都会对每一个变更进行代码审查,以获得至少两组关注。在我早期的一个工作中,我们做了一段时间的代码评审(很少),然后一个来自谷歌的新员工加入了我们,并鼓励我们评审我们所做的所有代码。这是一个伟大的决定。如果你做得对,代码评审就不会觉得繁重。你和你的审稿人不是对手;你们在一起工作,共同构建最好的软件。不要把反馈当成针对个人的,这一点很重要
- 本文作者: Littleki
- 本文链接: https:/littleki.gitee.io/2020/03/19/分享会/微码分享会/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!