

vue3.0
vite
vite 中动态引入路径
1 | <img :src="getSrc('123')"> |
vue3 碰到的问题
1. 源码里的 lazy作用?
- 懒加载作用、惰性
- 在默认情况下,v-model 在每次 input 事件触发后将输入框的值与数据进行同步 (除了上述输入法组织文字时)。你可以添加 lazy 修饰符,从而转为在 change 事件_之后_进行同步:
1
2
3<!-- 在“change”时而非“input”时更新 -->
<input v-model.lazy="msg" />
{{msg}}
输入input 焦点离开input 时 msg 才会更新
2. Proxy 只对最外层对象代理?
Proxy 只对最外层对象代理,如果对象里的子元素是对象,则要对其做响应代理
1 | if (isObject(res)) { |
3. 源码里的 cleanup 作用?
- cleanup() 的逻辑其实在Vue 2x的源码中也有的,避免依赖的重复收集。
为什么 Vue3 没有直接编译到原生 DOM?
- 不想放弃 Virtual DOM 的表达能力
- 兼容 Vu2
@vue/compat - Virtual DOM 也不一定慢
意义:单个组件分发
为什么引入组合式 API?
源码里为什么优先取值 setup 里的值
1 | export{ |
Vue3 项目结构
reactivity: 响应式系统compiler-core: 与平台无关的编译器核心compiler-dom: 针对浏览器的编译模块compiler-sfc: 针对单文件解析runtime-core: 与平台无关的运行时核心runtime-dom: 针对浏览器运行时。包括DOM API,属性、事件等等compiler-ssr: 针对服务端渲染的编译模块runtime-test: 用于测试server-renderer: 用于服务端渲染sfc-playground: xxxshared: 多个包之间的共享内容size-check: 用来测试代码体积template-explorer: 用于调试编译器调试工具
Monorepo
Monorepo 简单的说,是指将公司的所有代码放到一个 Git / Mercurial / Subversion 的代码仓库中。对于很多没听说过这个概念的人而言,无异于天方夜谭。Git 仓库不应该是每个项目一个吗?对于很多用 monorepo 的公司,他们的 Git 仓库中不止有自己的代码,还包括了很多的依赖。基本上,只要把 monorepo 用 Git 拖下来,跑一下 ./scripts/install,就可以直接用 Buck / Bazel (在安装脚本中就装到了本地)编译仓库中的所有项目,并且提交修改(安装脚本配置好了代码提交环境,如果用的 Phabricator 的话,Gerrit 不用)。
Monorepo 的核心观点是所有的项目在一个代码仓库中。这并不是说代码没有组织都放在 ./src 文件夹里面。相反,通过使用 Buck / Bazel,monorepo 中的代码都是分割到一个个小的模块中的。
一个仓库维护多个模块,方便版本和依赖管理,模块之间的引用
参考链接
Vue3项目知识点
package.json workspaces 包的文件目录
使用 yarn 作为包管理器的,可以在 package.json 中以 workspaces 字段声明 packages,yarn 就会以 monorepo 的方式管理 packages。相比 lerna,yarn 突出的是对依赖的管理,包括 packages 的相互依赖、packages 对第三方的依赖,yarn 会以 semver 约定来分析 dependencies 的版本,安装依赖时更快、占用体积更小;但欠缺了「统一工作流」方面的实现。
yarn 官网对 workspace的详细说明:Workspaces | Yarn
安装整个项目的依赖和常规的 yarn 用法一样,直接 yarn install 就完事了。
如果你想安装一个依赖,那么分下面三种场景:
yarn workspaces add package:给所有应用都安装依赖
yarn workspace project add package:给某个应用安装依赖
yarn add -W -D package:给根应用安装依赖
workspaces 是 yarn 相对 npm 的一个重要优势(另一个优势是下载更快),它允许我们使用 monorepo 的形式来管理项目。
参考链接:https://www.imooc.com/article/315212
编译阶段的优化
1 | 1. <script setup> |
shallowReactive
创建一个响应式代理,它跟踪其自身 property 的响应性,但不执行嵌套对象的深层响应式转换 (暴露原始值)。
- 有些值不应该是响应式的,例如复杂的第三方类实例或 Vue 组件对象。
- 当渲染具有不可变数据源的大列表时,跳过 proxy 转换可以提高性能。
- 当对象里的父及基础类型发生改变,则当前对象里在视图也会被更新
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19setup() {
window.shallowReactiveState = shallowReactive(({
name: 'cxx',
age: {
number: 99
}
}))
setTimeout(() => {
shallowReactiveState.age.number = 1000
}, 1000);
setTimeout(() => {
shallowReactiveState.name = 'zmj'
}, 2000);
return {
shallowReactiveState,
changeName,
changeAge
}
}
apiWatch
watch => doWatch(source, cb, { immediate, deep, flush, onTrack, onTrigger } = EMPTY_OBJ, instance = currentInstance)
1 | function watch(source, cb, options) { |
doWatch => runner => recordInstanceBoundEffect(runner, instance)
1 | const runner = effect(getter, { |
1 | import { ref, watch } from 'vue' |
以下是等效的选项式 API:
1 | export default { |
apiComputed
computed => new ComputedRefImpl() => recordInstanceBoundEffect()computed 类似于 ref
1 | export function computed<T>( |
因为 computed 返回的是 ComputedRefImpl 所以定义 computed 的值要 data.value才能取到
1 | import { ref, computed } from 'vue' |
ComputedRefImpl 源码
1 | class ComputedRefImpl { |
@vue/runtime-core/distruntime-core.cjs
publicPropertiesMap
vue 公共属性
1 | const publicPropertiesMap = shared.extend(Object.create(null), { |
Diff
一、Diff作用
diff作用就是在patch子vnode过程中,找到与新vnode对应的老vnode,复用真实的dom节点,避免不必要的性能开销
- vue3在DOM-Diff过程中,根据 newIndexToOldIndexMap 新老节点索引列表找到最长稳定序列,通过最长增长子序列的算法比对,找出新旧节点中不需要移动的节点,原地复用,仅对需要移动或已经patch的节点进行操作,最大限度地提升替换效率,相比于Vue2版本是质的提升!
二、patchKeyedChildren
- 从头对比找到有相同的节点 patch ,发现不同,立即跳出
- 如果第一步没有patch完,立即,从后往前开始patch ,如果发现不同立即跳出循环(经历第一步操作之后,如果发现没有patch完,那么立即进行第二部,从尾部开始遍历依次向前diff。如果发现不是相同的节点,那么立即跳出循环。)
- 如果新的节点大于老的节点数 ,对于剩下的节点全部以新的vnode处理( 这种情况说明已经patch完相同的vnode )
- 如果新节点全部被patch,老节点有剩余,那么卸载所有老节点
- 不确定的元素 ( 这种情况说明没有patch完相同的vnode ),我们可以接着①②的逻辑继续往下看
- 把没有比较过的新的vnode节点,通过map保存
- 遍历剩下的旧节点,找到胃patc的节点,匹配节点,移除不再存在的节点
- 只在节点移动时生成最长稳定子序列(longest stable subsequence == 最长稳定子序列 )
newIndexToOldIndexMap找到对应新老节点关系
到这里,我们patch了一遍,把所有的老vnode都patch了一遍。
最长稳定子序列(longest stable subsequence)
首选通过getSequence 函数生成一个最长稳定序列,对于index === 0 的情况也就是新增节点(图中I) 需要从新mount一个新的vnode,然后对于发生移动的节点进行统一的移动操作
什么叫做最长稳定序列
对于以下的原始序列
0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15
最长递增子序列为
0, 2, 6, 9, 11, 15.
为什么要得到最长稳定序列
- 因为我们需要一个序列作为基础的参照序列,其他未在稳定序列的节点,进行移动。
总结
从头对比找到有相同的节点 patch ,发现不同,立即跳出。
如果第一步没有patch完,立即,从后往前开始patch ,如果发现不同立即跳出循环。
如果新的节点大于老的节点数 ,对于剩下的节点全部以新的vnode处理( 这种情况说明已经patch完相同的vnode )。
对于老的节点大于新的节点的情况 , 对于超出的节点全部卸载 ( 这种情况说明已经patch完相同的vnode )。
不确定的元素( 这种情况说明没有patch完相同的vnode ) 与 3 ,4对立关系。
1 把没有比较过的新的vnode节点,通过map保存
记录已经patch的新节点的数量 patched
没有经过 path 新的节点的数量 toBePatched
建立一个数组newIndexToOldIndexMap,每个子元素都是[ 0, 0, 0, 0, 0, 0, ] 里面的数字记录老节点的索引 ,数组索引就是新节点的索引。 0是默认先代表此节点为新增节点。
开始遍历老节点
① 如果 toBePatched新的节点数量为0 ,那么统一卸载老的节点
② 如果,老节点的key存在 ,通过key找到对应的index
③ 如果,老节点的key不存在
1 遍历剩下的所有新节点
2 如果找到与当前老节点对应的新节点那么 ,将新节点的索引,赋值给newIndex
④ 没有找到与老节点对应的新节点,卸载当前老节点。
⑤ 如果找到与老节点对应的新节点,把老节点的索引,记录在存放新节点的数组中,
1 如果节点发生移动 记录已经移动了
2 patch新老节点 找到新的节点进行patch节点
遍历结束
如果发生移动
① 根据 newIndexToOldIndexMap 新老节点索引列表找到最长稳定序列
② 对于 newIndexToOldIndexMap -item =0 证明不存在老节点 ,从新形成新的vnode
③ 对于发生移动的节点进行移动处理。
三、key的作用,如何正确key。
1key的作用
在我们上述diff算法中,通过isSameVNodeType方法判断,来判断key是否相等判断新老节点。
那么由此我们可以总结出?
在v-for循环中,key的作用是:通过判断newVnode和OldVnode的key是否相等,从而复用与新节点对应的老节点,节约性能的开销。
2如何正确使用key
错误用法
1、用index做key。
- 用index做key的效果实际和没有用diff算法是一样的
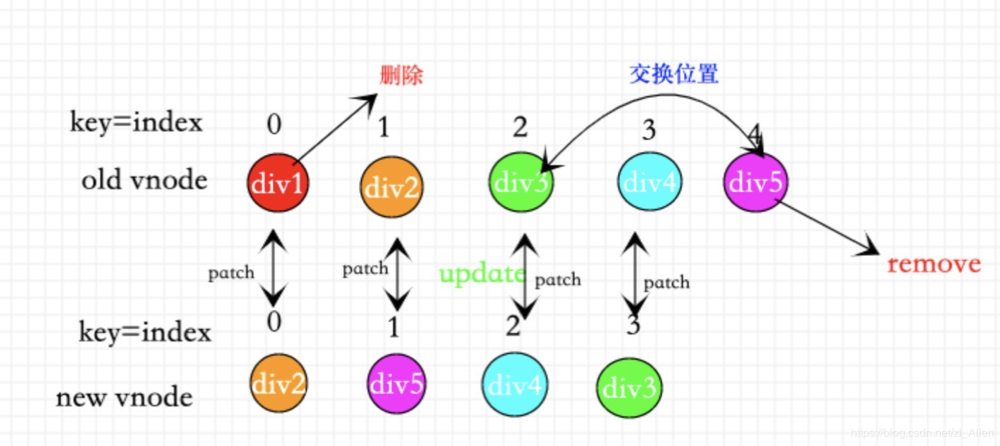
如果所示当我们用index作为key的时候,无论我们怎么样移动删除节点,到了diff算法中都会从头到尾依次patch(图中:所有节点均未有效的复用)
2、:用index拼接其他值作为索引。
当已用index拼接其他值作为索引的时候,因为每一个节点都找不到对应的key,导致所有的节点都不能复用,所有的新vnode都需要重新创建。都需要重新create
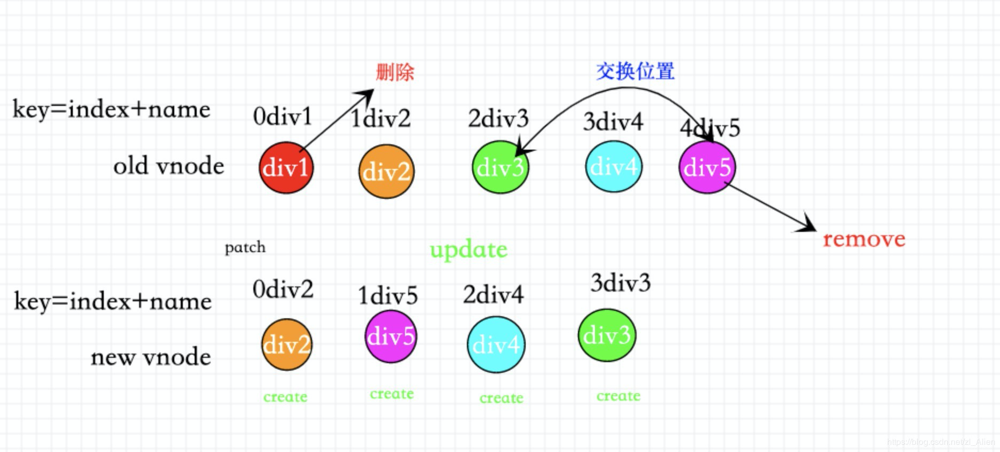
正确用法
正确用法 :用唯一值id做key(我们可以用前后端交互的数据源的id为key)。
如图所示。每一个节点都做到了复用。起到了diff算法的真正作用。
key的作用就是更新组件时判断两个节点是否相同。相同就复用,不相同就删除旧的创建新的。如果不添加key组件默认都是就地复用,不会删除添加节点,只是改变列表项中的文本值,要知道节点操作是十分耗费性能的。而添加了key之后,当对比内容不一致时,就会认为是两个节点,会先删除掉旧节点,然后添加新节点。
没有key时,前3个节点复用,只修改值,在最后添加了一个新节点
key=”i”时,当新节点的key与旧的key相同时,则复用旧节点,key为0,1,2的节点会复用旧节点,选中的节点为key=”1”,
key=”item.id”时,此id为唯一值,所以其它3个旧节点都会复用
- 如果只是交换顺序,key用 i 或者不用的性能比较好,因为只是改变节点的值,这个默认的模式是高效的,但是只适用于不依赖子组件状态或临时 DOM 状态 (例如:表单输入值) 的列表渲染输出。
- 如果会增删数据,key用唯一标识的性能比较好,vue根据这唯一的key跟踪每个节点的身份,从而重用和重新排序现有元素,新节点的key与旧节点key相同时,会直接复用
patchKeyedChildren 思维导图

patchUnkeyedChildren
1 | const patchUnkeyedChildren = ( |
PatchFlags.KEYED_FRAGMENT
- vue3 引入碎片概念
- 在 3.x 中,组件可以包含多个根节点!不在像ue2.x需要唯一根结点
vue2.x1
2
3
4
5
6
7
8<!-- Layout.vue -->
<template>
<div>
<header>...</header>
<main v-bind="$attrs">...</main>
<footer>...</footer>
</div>
</template>
vue3.x
1 | <!-- Layout.vue --> |
- flagment出现就是用看起来像一个普通的DOM元素,但它是虚拟的,根本不会在DOM树中呈现。这样我们可以将组件功能绑定到一个单一的元素中,而不需要创建一个多余的DOM节点。
1
2
3
4
5<Fragment>
<span> 苹果🍎 </span>
<span> 香蕉🍌 </span>
<span> 鸭梨🍐 </span>
</Fragment>
组件创建过程
- 第一次 patch 的触发,就是在组件创建的过程。只不过此时,oldVNode 为 null,所以会表现为挂载的行为。
开始 => createApp => createRenderer => baseCreateRenderer => mount => render => patch => processComponent => mountComponent => [- createComponentInstance : ComponentInternalInstance
- setupComponent => setupStatefulComponent(执行
setup) => finishComponentSetup, - setupRenderEffect => componentEffect => renderComponentRoot => render
]
setupStatefulComponent 里会执行 option 里 setup 函数, finishComponentSetup 里生成 render 函数
setupRenderEffect 里会给 instance 添加update 方法,通过响应式方法 effect 创建 componentEffect
也就是说每个组件都有自己的副作用函数 componentEffect
componentEffect => renderComponentRoot => 执行render函数(render 里收集响应式依赖)
vue3 源码初始化流程

大致渲染流程
首次渲染阶段 setupRenderEffect —> 通过响应式API Effect 创建副作用函数 componentEffect —> 组件数据更新时 componentEffect 重新调用 —> 进入 diff 流程
instance 通过 createComponentInstance 方法创建
1 | // runtime-core/src/renderer.ts |
1 | type PatchFn = ( |
connectedCallback —-> mounted
disconnectedCallback —-> unmounted
Vue2.x
Vue.set 的实现
1 | * triggers change notification if the property doesn't |
注意:数组的变化也是执行 ob.dep.notify()手动触发依赖 ,视图更新
Vue3.2 响应式优化
- More efficient ref implementation (~260% faster read / ~50% faster write)
ref API 的读效率提升约为 260%,写效率提升约为 50% - ~40% faster dependency tracking
依赖收集的效率提升约为 40% - ~17% less memory usage
同时还减少了约 17% 的内存使用
思考?
- 如何提高读写效率?
- 如何提升依赖收集的效率?
- 如何减少内存使用?
- 位运算介绍和运用场景
- ReactiveEffect 函数 3.2和3.1 差异
减少内存使用跟依赖收集是有一定的关系的
如何收集依赖
- 然后触发 effect 里的回调函数
1 | import { reactive} from 'vue' |
effect(收集依赖 track) –> count (Update,执行 trigger ) –> 触发其对应的依赖响应,执行logCount
Vue3响应式流程
effect 函数作用流程图
依赖收集过程
- effect的概念,代表某个动作引起的额外效果/影响。(当effect执行后,会建立起数据和fn的依赖关系,数据变更后触发fn执行)
- 依赖关系建立过程
- effect(fn)(在mount挂载的时候,对把update作为参数fn执行effect函数)
- fn入栈(effectStack)
- 执行一次fn
- fn函数中使用响应式数据,触发依赖(get)
- 触发track函数,存储依赖
- targetMap.get(target)=>depMap.get(key)=>deps。 fn存入deps中
- effectStack出栈,结束依赖关系建立
- 数据变更触发更新
- 响应式数据更新,触发set函数
- 触发trigger函数
- targetMap.get(target)=>depMap.get(key)=>deps。遍历deps并且执行(deps内存的为所有的依赖)
收集依赖的时机?
1 | function pauseTracking() { |
cleanup 的作用
1 | <template> |
结合代码可以知道,这个组件的视图会根据 showMsg 变量的控制显示 msg 或者一个随机数,当我们点击 Switch View 的按钮时,就会修改这个变量值。
假设没有 cleanup,在第一次渲染模板的时候,activeEffect 是组件的副作用渲染函数,因为模板 render 的时候访问了 state.msg,所以会执行依赖收集,把副作用渲染函数作为 state.msg 的依赖,我们把它称作 render effect。然后我们点击 Switch View 按钮,视图切换为显示随机数,此时我们再点击 Toggle Msg 按钮,由于修改了 state.msg 就会派发通知,找到了 render effect 并执行,就又触发了组件的重新渲染。
但这个行为实际上并不符合预期,因为当我们点击 Switch View 按钮,视图切换为显示随机数的时候,也会触发组件的重新渲染,但这个时候视图并没有渲染 state.msg,所以对它的改动并不应该影响组件的重新渲染。
因此在组件的 render effect 执行之前,如果通过 cleanup 清理依赖,我们就可以删除之前 state.msg 收集的 render effect 依赖。这样当我们修改 state.msg 时,由于已经没有依赖了就不会触发组件的重新渲染,符合预期。
更好的依赖收集
- 之前key被收集,但是当前没有收集,则在key关联的Dep中删除除当前effect
- 之前key没有被收集,当时当前被收集,则在key关联的Dep中添加当前effect`
- 之前key被收集,当前也被收集,则保持不变
initDepMarkers 函数
1
2
3
4
5
6
7const initDepMarkers = ({ deps }) => {
if (deps.length) {
for (let i = 0; i < deps.length; i++) {
deps[i].w |= trackOpBit // 标记依赖已经被收集
}
}
}
initDepMarkers 遍历 _effect 实例中的 deps 属性,给每个 dep 的 w 属性标记为 trackOpBit 的值。
trackEffects
1 | function trackEffects(dep, debuggerEventExtraInfo) { |
- trackEffects 会判断当前依赖是否是新收集的依赖,如果不是则把当前依赖变成 新收集的依赖
- shouldTrack = !wasTracked(dep) 如果依赖已经被收集,则不需要再次收集
finalizeDepMarkers 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20const finalizeDepMarkers = (effect) => {
const { deps } = effect
if (deps.length) {
let ptr = 0
for (let i = 0; i < deps.length; i++) {
const dep = deps[i]
// 曾经被收集过但不是新的依赖,需要删除
if (wasTracked(dep) && !newTracked(dep)) {
dep.delete(effect)
}
else {
deps[ptr++] = dep
}
// 清空状态
dep.w &= ~trackOpBit
dep.n &= ~trackOpBit
}
deps.length = ptr
}
}
- shouldTrack = !wasTracked(dep) 如果依赖已经被收集,则不需要再次收集
finalizeDepMarkers 主要做的事情就是找到那些曾经被收集过但是新的一轮依赖收集没有被收集的依赖,从 deps 中移除。这其实就是解决前面举的需要 cleanup 的场景:在新的组件渲染过程中没有访问到的响应式对象,那么它的变化不应该触发组件的重新渲染。
响应式 ref、computed API 的优化
vue3.1.x
1 | function track(target: object, type: TrackOpTypes, key: unknown) { |
vue3.2.x
1 | export function trackRefValue(ref: RefBase<any>) { |
- 对于 ref ,那个老外
Bas van Meurs把依赖挂载自身身上, - 不需要再通过 trigger 函数额外的的逻辑,这样就能提高性能
- 就是副作用函数使用位运算,减少相关的逻辑判断
相关函数
1 | const maxMarkerBits = 30 // 表示最大标记的位数。最多30个互相引用,如果超出则清理 |
- allowRecurse参数是针对scheduler的
- vue通过targetMap将effect和收集的target和key建立关系。
- key通过Dep与effect建立关系,effect通过缓存deps与key建立关系
- effect的deps管理方式有两种,effect层叠数少于30时通过w、n状态细粒增删,超过30则进入前删,后续都是增
总结
本次优化主要是通过ref 存储自身的 dep, 把自身的dep 传给 trackEffect
不用再通过 depMaps.get(key)取 ref 依赖,进而提高更新依赖的效率通过位运算,给每个收集的 dep 做标记,
把当前没有要收集并且收集过的依赖删除自身的副作用函数 effect
第二次收集依赖的时候,如果当前依赖被收集过,则不需要再次收集
优化了,不再重复收集依赖,把需要的依赖保留住,这样减少了 删除自身的副作用函数 effect的次数,以及不需要再重新收集依赖,进而提升依赖收集的效率
参考链接
(https://bill-lai.github.io/article/37495e00ab36e870f8dd/)[https://bill-lai.github.io/article/37495e00ab36e870f8dd/]
(https://zhuanlan.zhihu.com/p/401416696)[https://zhuanlan.zhihu.com/p/401416696]
(https://blog.csdn.net/qq_27368993/article/details/120821486)[https://blog.csdn.net/qq_27368993/article/details/120821486]
- 本文作者: Littleki
- 本文链接: https:/littleki.gitee.io/2020/10/15/Vue3-0-笔记/vue3-源码笔记/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!