

数据结构与算法之美
一、什么是复杂度分析?
1.数据结构和算法解决是“如何让计算机更快时间、更省空间的解决问题”。
2.因此需从执行时间和占用空间两个维度来评估数据结构和算法的性能。
3.分别用时间复杂度和空间复杂度两个概念来描述性能问题,二者统称为复杂度。
4.复杂度描述的是算法执行时间(或占用空间)与数据规模的增长关系。
二、为什么要进行复杂度分析?
1.和性能测试相比,复杂度分析有不依赖执行环境、成本低、效率高、易操作、指导性强的特点。
2.掌握复杂度分析,将能编写出性能更优的代码,有利于降低系统开发和维护成本。
三、如何进行复杂度分析?
1.大O表示法
1)来源
算法的执行时间与每行代码的执行次数成正比,用T(n) = O(f(n))表示,其中T(n)表示算法执行总时间,f(n)表示每行代码执行总次数,而n往往表示数据的规模。
2)特点
以时间复杂度为例,由于时间复杂度描述的是算法执行时间与数据规模的增长变化趋势,所以常量阶、低阶以及系数实际上对这种增长趋势不产决定性影响,所以在做时间复杂度分析时忽略这些项。
2.复杂度分析法则
1)单段代码看高频:比如循环。
2)多段代码取最大:比如一段代码中有单循环和多重循环,那么取多重循环的复杂度。
3)嵌套代码求乘积:比如递归、多重循环等
4)多个规模求加法:比如方法有两个参数控制两个循环的次数,那么这时就取二者复杂度相加。
四、常用的复杂度级别?
多项式阶:随着数据规模的增长,算法的执行时间和空间占用,按照多项式的比例增长。包括,
O(1)(常数阶)、O(logn)(对数阶)、O(n)(线性阶)、O(nlogn)(线性对数阶)、O(n^2)(平方阶)、O(n^3)(立方阶)
非多项式阶:随着数据规模的增长,算法的执行时间和空间占用暴增,这类算法性能极差。包括,
O(2^n)(指数阶)、O(n!)(阶乘阶)
五、如何掌握好复杂度分析方法?
复杂度分析关键在于多练,所谓孰能生巧。
什么是数组?
数组在逻辑上是一种线性表数据结构. 数组在物理上是一种顺序的存储结构. 数组的定义: 数组(Array)是一种线性表数据结构,它用一组连续的内存空间,来存储一组具有相同类型的数据. 数组定义的关键词: 1.连续的内存空间 2. 相同类型的数据. 在此提一下何为线性表: 线性表: 数据排成像一条线一样的结构.每个线性表上的数据最多只有前和后两个方向. 非线性表: 数据之间并不是简单的前后关系. 线性表数据结构包括: 数组,链表,队列,栈. 非线性表数据结构包括: 二叉树,堆,图
数组和链表的区别?
即便是排好序的数组,你用二分查找,时间复杂度也是O(logn),所以正确的表述是:数组支持随机访问,根据下标随机访问的时间复杂度是O(1)。
JVM垃圾回收算法:
- 复制算法.
- 标记清除算法.
- 标记整理算法. 简单思想: 数组中删除数据时,并不真正的删除,而是标记一下,先不进行数据的搬移工作,等数组空间不够用时,我们再执行删除操作.进行数据的搬移工作. –> 这样可以减少因为删除操作导致的数据搬移. 这种思想在JVM垃圾回收算法的 标记清除算法中 也有体现. 第一遍扫描先标记垃圾对象,第二遍扫描再清除垃圾对象. –> 这种垃圾回收算法 容易产生内存碎片,导致出现虽然内存空间充足,但是无法放置大对象的诡异现象.
缓存概念
硬件中的缓存:
CPU缓存,而cpu缓存又可以分为寄存器,一级缓存,二级缓存,三级缓存。 软件中的缓存: 数据库缓存,数据库本身产品就自带缓存。redis也可以作为数据库缓存. 浏览器缓存,就是我们常说的Cookie,本质上就是一个文件。
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?
常见的策略有三种:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
FIFO(先进先出调度器) 、Capacity Scheduler(容量调度器)和 Fair Sceduler(公平调度器)。
链表 VS 数组性能大比拼
通过前面内容的学习,你应该已经知道,数组和链表是两种截然不同的内存组织方式。正是因为内存存储的区别,它们插入、删除、随机访问操作的时间复杂度正好相反。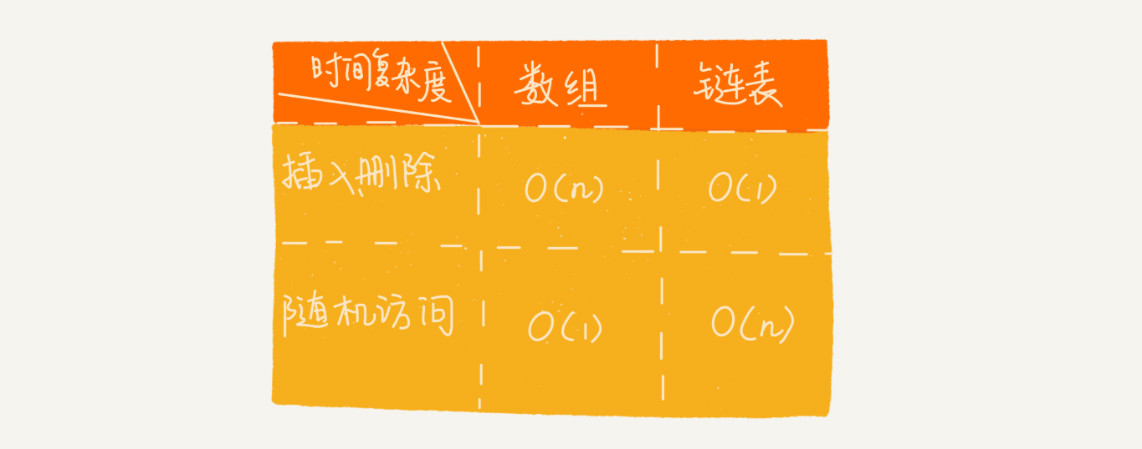
- 本文作者: Littleki
- 本文链接: https:/littleki.gitee.io/2020/11/04/数据结构与算法之美/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!